
Redis7

Redis7
NuyoahRedis7入门概述
Remote Dictionary Server(远程字典服务)是完全开源的,使用ANSIC语言编写遵守BSD协议,是一个高性能的Key-Value数据库提供了丰富的数据结构,例如String、Hash、List、Set、SortedSet等等。数据是存在内存中的,同时Redis支持事务、持久化、LUA脚本、发布/订阅、缓存淘汰、流技术等多种功能特性提供了主从模式、Redis Sentinel和Redis Cluster集群架构方案
Redis是一种缓存技术
- 分布式缓存,挡在mysql数据库之前的带刀护卫
- 内存存储和持久化(RDB+AOF), redis支持异步将内存中的数据写到硬盘上,同时不影响继续服务
- 高可用架构搭配
- 缓存穿透、击穿、雪崩
- 分布式锁
- 队列
- 排行版+点赞
- …
数据库遵循 2(写)- 8(读)原则,为了让这两个保持平衡,我们使用redis缓存,将8(读)进行降低。
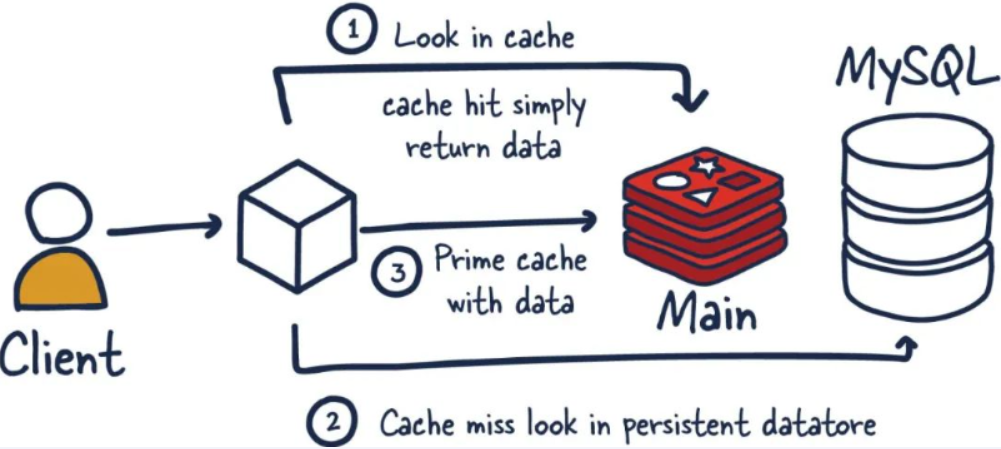
与传统数据库关系(mysql)
-
Redis是key-value数据库(NoSQL一种),mysql是关系数据库
-
Redis数据操作主要在内存,而mysql主要存储在磁盘
-
Redis在某一些场景使用中要明显优于mysql,比如计数器、排行榜等方面
-
Redis通常用于一些特定场景,需要与Mysql一起配合使用
-
两者并不是相互替换和竞争关系,而是共用和配合使用
优势
- 性能极高 - Redis能读的速度是110000次/秒,写的速度是81000次/秒
- Redis数据类型丰富,不仅仅支持简单的key-value类型的数据
- 同时还提供list,set,zset,hash等数据结构的存储
- Redis支持数据的持久化,可以将内存中的数据保持在磁盘中
- 重启的时候可以再次加载进行使用
- Redis支持数据的备份,即master-slave模式的数据备份
下载
官网:www.redis.cn
github:Release 7.2.4 · redis/redis (github.com)
文档资料:
版本号第二位如果是奇数,则为非稳定版本 如2.7、2.9、3.1
版本号第二位如果是偶数,则为稳定版本 如2.6、2.8、3.0、3.2
当前奇数版本就是下一个稳定版本的开发版本,如2.9版本是3.0版本的开发版本
安装
-
下载获得redis-7.0.0.tar.gz后将它放入我们的Linux目录/opt
opt文件夹寻找方法:
- ctrl + alt + t 打开终端
- cd …/ 返回上一层目录
- cd …/ 返回上一层目录
- ls 就能看到opt
-
/opt目录下解压redis
tar -zxvf redis-7.0.0.tar.gz
-
进入 redis文件夹
-
在redis中执行 make && make install,make可能需要下载,按照终端提示就行
-
默认安装目录:在opt同级文件夹下的 usr/local/bin
- redis-benchmark:性能测试工具,服务启动后运行该命令,看看自己本子性能如何
- redis-check-aof: 修复有问题的AOF文件,rdb和aof后面讲
- redis-check-dump: 修复有问题的dump.rdb文件
- redis-cli: 客户端,操作入口
- redis-sentinel: redis集群使用
- Redis服务器启动命令
- redis-server:
-
将默认的redis.conf拷贝到自己定义好的一个路径下,比如/myredis
-
修改/myredis目录下redis.conf配置文件做初始化设置
redis.conf配置文件,改完后确保生效,记得重启,记得重启
使用vim修改
vim打开操作:vim 需要打开的文件夹
vim查找操作:/查找的字符串,查到之后按回车,然后通过n查找下一个,N查找上一个
vim插入操作:i,修改完毕之后使用esc退出
vim退出操作::wq!
- 默认daemonize no 改为 daemonize yes
- 默认protected-mode yes 改为 protected-mode no
- 默认bind 127.0.0.1 改为 直接注释掉(默认bind 127.0.0.1只能本机访问)或改成本机IP地址,否则影响远程IP连接
- 添加redis密码 改为 requirepass 你自己设置的密码
启动服务
-
使用/myredis中修改完的配置文件启动redis
redis-server /myredis/redis7.conf
ps -ef|grep redis|grep -v grep
-
连接服务
redis- server /myredis/redis.conf // 启动服务端
redis-cli -a 密码 -p 端口 // 连接服务
-
设置KV键值对
set k1 helloword
get k1
删除Redis
-
停止所有redis服务
ps -ef|grep redis|grep -v grep // 查看redis服务
redis-cli shutdown // 关闭服务
ps -ef|grep redis|grep -v grep // 查看是否关闭
-
删除usr/local/lib目录下与redis相关的所有文件
ls -l /usr/local/bin/redis-* // 查看对应目录下所有redis开头的文件
rm -rf /usr/local/bin/redis-* // 删除对应目录先所有redis开头的文件
Redis的10大数据类型
官网查阅:Commands | Docs (redis.io)
类型:
redis字符串—String
string是redis最基本的类型,一个key对应一个value。
string类型是二进制安全的,意思是redis的string可以包含任何数据,比如jpg图片或者序列化的对象 。
string类型是Redis最基本的数据类型,一个redis中字符串value最多可以是512M
redis列表—List
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
它的底层实际是个双端链表,最多可以包含 2^32 - 1 个元素 (4294967295, 每个列表超过40亿个元素)
redis哈希表—Hash
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
Redis 中每个 hash 可以存储 2^32 - 1 键值对(40多亿)
redis集合—Set
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据,集合对象的编码可以是 intset 或者 hashtable。
Redis 中Set集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
集合中最大的成员数为 2^32 - 1 (4294967295, 每个集合可存储40多亿个成员)
redis有序集合—ZSet
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数,redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
zset集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。 集合中最大的成员数为 2^32 - 1
redis地理空间—GEO
Redis GEO 主要用于存储地理位置信息,并对存储的信息进行操作,包括
添加地理位置的坐标。
获取地理位置的坐标。
计算两个位置之间的距离。
根据用户给定的经纬度坐标来获取指定范围内的地理位置集合
redis基数统计—HyperLogLog
HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
redis位图—bitmap
由0和1状态表现的二进制位的bit数组

redis位域—bitfield
通过bitfield命令可以一次性操作多个比特位域(指的是连续的多个比特位),它会执行一系列操作并返回一个响应数组,这个数组中的元素对应参数列表中的相应操作的执行结果。
说白了就是通过bitfield命令我们可以一次性对多个比特位域进行操作。
redis流—Stream
Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。
简单来说发布订阅 (pub/sub) 可以分发消息,但无法记录历史消息。
而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失
redis常用命令
| 命令 | 描述 |
|---|---|
| keys * | 查看当前库中的所有key |
| exists key | 判断某个key是否存在 |
| type key | 查看你的key是什么类型 |
| del key | 删除指定的key数据 |
| unlink key | 非阻塞删除,仅仅将keys充keysspace元数据中删除 真正的删除会在后续异步中操作 |
| ttl key | 查看还有多少秒过期,-1表示永不过期,-2表示已过期 |
| expire key(单位:秒) | 为指定的key设置过期时间 |
| move key dbindex[0-15] | 将当前数据库的key移动到给定的数据库db中 |
| select dbindex | 切换数据库0-15,默认为0 |
| dbsize | 查看当前数据库key的数量 |
| flushdb | 清空当前数据库 |
| flushall | 通杀全部库 |
数据类型命令及落地运用
Redis命令不区分大小写,Key区分大小写
help @类型,help @String
String
-
set key value
set key value [NX|XX] [GET] [EX seconds|PX milliseconds|EXAT unix-time- seconds | PXAT unix- time- milliseconds |KEEPTTL ]
SET命令有EX、PX、NX、x以及KEEPTTL五个可选参数,其中KEEPTTL为6.0版本添加的可选参数,其它为2.6.12版本添加的可选参数。
- EX seconds:以秒为单位设置过期时间
- Px milliseconds:以毫秒为单位设置过期时间
- EXAT timestamp:设置以秒为单位的UNIX时间戳所对应的时间为过期时间
- PXAT milliseconds-timestamp: 设置以毫秒为单位的UNIX时间戳所对应的时间为过期时间
- NX:键不存在的时候设置键值
- XX:键存在的时候设置键值
- KEEPTTI:保留设置前指定键的生存时间
- GET:返回指定键原本的值,若键不存在时返回nil
SET命令使用EX、EX、NX参数,其效果等同于SETEX、PSETEX、SETNX命令。根据官方文档的描述,未来版本中SETEX、PSETEX、SETNX命令可能会被淘汰。
EXAT,PXAT以及GET为Redis 6.2新增的可选参数
返回值
设置成功则返回oK;返回ni1为未执行SET命令,如不满足NX、XX条件等
若使用GET参数,则返回该键原来的值,或在键不存在时返回nil。
- set key value NX: 在key没有存在的时候能够设置成功,当key存在的时候无法设置成功
- set key value XX:在key已存在的时候设置成功,不存在的时候无法设置成功
- set key value get:在给key设置的时候,先返回key的值,然后再将value的值存入key中
- set key value EX 10: 在设置key设置的时候,设置过期时间 EX为秒
- set key value PX 10:在设置key设置的时候,设置过期时间 PX为毫秒
- set key value EXAT 10:以时间戳为过期时间
- set key value keepttl:设置key的时候,继承上一次的key设置时间
-
get key
-
同时设置/获取多个键值
- mset:同时设置多个键值对-----mset k1 v1 k2 v2
- mget:通过获取多个值-------mget k1 k2 k3
- msetnx:设置多个值,key必须存在才能设置成功
-
获取指定区间范围的值
-
getrange:获取指定字符串的特定位置的字符
set k1 123456789
getrange k1 0 -1 // 获取所有字符串
getrange k1 3 8 // 获取索引在3-8之间的所有字符
-
setrange:设置指定字符串特定位置的字符串
set k1 123456789
settrange k1 1 xy // 将索引为1的字符替换为xy
-
-
数值增减
- INCR key:递增数字,默认是1,INCR key 3,一次递增三
- DECR key:递减数字,默认是1,DECR key 3,一次递减三
-
获取字符串长度和内容增加
- STRLEN k1:获取k1中的字符串长度
- APPEND k1 xxx:向k1中的字符串后面添加xxx
-
分布式锁:
- 当有多个微服务同时争抢一个资源的时候可以使用redis来进行分布式锁
命令:
- setex key 过期时间 value,创建k-v键值对的时候设置过期时间
- setnx key value 如果key不存在才进行创建
-
getset 命令
getset key value:先将key的值取出来,然后在给它赋值新值
List
本质是双端列表,左边右边都可操作,有序
- 插入:
- LPUSH:从左边插入,LPUSH list1 1 2 3 4 5
- RPUSH:从右边插入,RPUSH list2 11 22 33 44 55
- 遍历:
- LRANGE KEY start stop:从左边遍历第一个参数是key,第二第三个参数是开始和结束的索引
- 删除
- LPOP:从左边弹出,LPOP list1
- RPOP:从右边弹出,RPOP list2
- 取元素
- LINDEX:按照索引取元素(从上到下),LINDEX KEY index
- 获取list长度
- LLEN:获取列表中元素的个数,LLEN key
- 删除指定元素
- LREM key 数字N 给定值V1,删除N个值为V1的元素,如果key中值V1的个数小于N则全部删除
- 截取list
- LTRIM key start stop, 截取key中位置从start 到 stop位置的元素
- 提取key1中的元素给key2
- RPOPLPUSH 源列表 目的列表,将源列表右边第一个元素提到目的列表左边第一个元素
- 替换指定位置的元素
- LSET key index value:将key中从左边开始算起index位置的元素替换成value
- 插入指定位置
- LINSERT key before/after 已有值 插入新值:在key列表中值为已有值的前面插入新值
Hash
K不变V是一个KV键值对
- 设置元素
- HSET key k1 v1 k2 v2:key是键 k1是键1
- HMSET key k1 v2 k2 v2:同时设置多个值
- HSETNX key k1 v1:存在则不添加,不存在则添加
- 获取元素
- HGET key k1:获取key中键为k1的值
- HMGET key k1 k2 k3:通过获取多个值
- HGETALL key :将key中的所有键值对遍历出来
- 删除元素
- HDEL key k1:将key中键为k1的删掉
- 获取某个KEY中的所有键值对的数量
- HLEN key
- 判断KEY中是否存在键为k1的键值对
- HEXISTS key k1
- 获取某个hash中的全部key,或者全部value
- HKEYS KEY:获取全部的键
- HVALS KEY:获取全部的值
- 增加整数或小数
- HINCRBY KEY K1 1:增加KEY的hash表中的值为K1的值加一
- HINCRBYFLOAT KEY K1 0.1
Set
单值多values,values不重复,无序
- 添加元素
- SADD KEY V1 V2 V3
- 遍历元素
- SMEMBERS KEY:将KEY中的元素全部遍历出来
- 查询数据元素是否存在
- SISMEMBER KEY value:判断value是否在KEY里面
- 删除元素
- SREM KEY VALUE:将KEY中值为VALUE的元素删除
- 通过集合里面有多少个元素
- SCARD KEY
- 随机获取集合中的元素,不会改变源集合
- SRANDMEMBER KEY NUM:随机展示KEY中数量为NUM的元素
- 随机获取集合中的元素,会改变源集合
- SPOP KEY NUM:随机展示KEY中数量为NUM的元素
- 数据迁移,将KEY中的数据迁移到KEY2中
- SMOVE KEY1 KEY2 value:将KEY1中的value迁移到KEY2中
- 集合运算
- 差集:SDIFF KEY1 KEY2:获取在KEY1中但不在KEY2中的元素
- 并集:SUNION KEY1 KEY2:获取KEY1和KEY2的并集
- 交集:SINTER KEY1 KEY2:获取即余数KEY1也属于KEY2的
ZSET
有序集合
在SET的基础上每一个VAL值前加一个score分数值,之前set是set K1 v1 v2 v3,现在ZSET是Zset k1 scor1e v1 score2 v2
- 添加元素
- ZADD:ZADD score 10 zhang 20 li,再添加元素的时候需要给元素设置上分数
- 获取元素
- 从小到大 获取元素的值:ZRANGE score 0 -1
- 从小到大 获取元素的值和分数:ZRANGE score 0 -1 WITHSCORES
- 从大到小 获取元素的值:ZREVRANGE score 0 -1
- 从小到大 获取元素的值和分数:ZREVRANGE score 0 -1 WITHSCORES
- 根据分数来获取元素:ZRANGEBYSCORE score 60 90 LIMIT 0 2,可以使用LIMIT来限制显示的个数
- 根据分数来获取元素和分数:ZRANGEBYSCORE score 60 90 WITHSCORE 默认是 60 <= 分数 <= 90 ,如果加上小括号则表示不包含断点分数 ZRANGEBYSCORE score (60 90 WITHSCORE
- 获取元素分数
- ZSCORE zset v2
- 获取集合中元素的个数
- ZCARD KEY
- 删除集合中的元素
- ZREM zset value
- 增加对应value的分数
- ZINCRBY key increment value:给值为value的元素添加increment 分
- 获取指定分数段的元素的个数
- ZCOUNT key min max
- 从ZET对象中第一个非空排序集中弹出一个或多个元素,他们是成员分数对
- ZMPOP myset MIN COUNT NUM:从myset中弹出最小的元素,弹出NUM个
- 获取对应元素下标
- ZRANK key values:获取values在key中的下标值 顺序
- ZREVRANK key values:获取values在key中的下标值 逆序
BitMap位图
用于状态判断
- 设置状态
- SETBIT bit1 index (0 or 1):给bit1的index位置设置为0或1
- 获取状态
- GETBIT bit1 index:获取bit1index位置的数据
- 获取bit的字节数
- STRLEN bit1:获取bit1的字节数,八位一组
- 获取bit键里面1的个数:
- BITCOUNT:全部键里面含有1的个数
- 对不同的二进制存储数据进行位运算
- BITOP OPERATION destkey key:OPERATION运算符包括:AND OR NOT XOR
HyperLogLog基数统计
去重统计功能的基数估计算法,**不能存储数据,之鞥呢发挥去重之后的基数个数 **
基数统计:统计一个集合中不重复的元素个数,就是对集合去重复后剩余元素的计算
- 添加元素
- PFADD hello1 1 3 4 5 7 9:
- 返回给定的HyperLogLog的基数估算值:
- PFCOUNT key
- 将多个HyperLogLog合并为一个HyperLogLog
- PFMERGE dest source1 source2
地理空间GEO
- 添加地理位置
- GEOADD city 精度 维度 地点
- 如果有乱码需要执行 redis-cli --raw命令来处理中文乱码
- 返回对应地理位置
- GEOPOS city 地点1 地点2
- 返回坐标用HASH表示:GEOHASH返回坐标用HASH表示
- 返回两个位置之间的距离
- GEODITS 地点1 地点2 (m, km)
- 以半径为中心返回查找附近的地点
- GEORADIUS city 经度 维度 10KM WITHDIST WITHCOORD WITHHASH COUNT
- WITHDIST:在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。 距离的单位和用户给定的范围单位保持一致。
- WITHCOORD:将位置元素的经度和维度也一并返回。
- WITHHASH:以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试实际中的作用并不大
- COUNT 限定返回的记录数
- 给定地点查找改地点周围的地点
- GEORADIUSMEMBER city 天安门 10KM WITHDIST WITHCOORD WITHHASH COUNT







