
计算机视觉

计算机视觉
NuyoahOpenCv简单应用
基本操作
- 图像读取:
1 | # 图像读取有两种格式 |
该方法返回值是一个 numpy 数组, 是一个三维数组
其含义分别是 y(竖直 h),x(水平 w), BGR(三原色), 在opencv中的色彩是BGR 不是RGB
- 图像的显示
1 | cv2.imshow("窗口名称", 图像数据) |
-
视频的读取
-
cv2.VideoCapture可以捕捉摄像头,用数字来控制不同的设备,例如0,1
-
如果是视频文件,直接指定好路径即可
-
1 | vc = cv2.VideoCapture("test.mp4") |
- 图像的截取
1 | img = cv2.imread("cat.jpg") |
- 颜色通道的获取
1 | # 因为Opencv的颜色为BGR |
- 图像的合并:
1 | img = cv2.merge((b, g, r)) |
-
图像颜色的改变
1
2
3
4
5
6
7# 变成红色 只要把对应的蓝色和绿色通道变为0即可
cur_img = img.copy()
# B 通道
cur_img[:,:,0] = 0
# G 通道
cur_img[:,:,1] = 0 -
边界的填充
使用函数 copyMakeBorder(图像数据, 上扩展大小, 下扩展大小, 左扩展大小,右扩展大小, 填充方法)
- BORDER_REPLICATE: 复制法,也就是复制最边缘的像素
- BORDER_REFLECT: 反射法,对感兴趣的图像中的像素在两边进行复制,如: fedcba | abcdefgh | hgfedcb
- BORDER_REFLECT_101: 反射法,也就是以最外边缘像素为轴,对称,例如,gfedcb | abcdefgh | gfedcba
- BORDER_WRAP: 外包装法,cdefgh | abcdefgh | abcdefg
- BORDER_CONSTANT: 常量法,常数值填充
1
2
3
4
5
6
7
8
9
10
11
12# 先确定上下左右扩展的大小
top_size, bottom_size, left_size,right_size = (50,50,50,50)
# 以下是五种扩展方法方法
replicate = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, borderType = cv2.BORDER_REPLICATE)
reflect = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, borderType = cv2.BORDER_REFLECT)
reflect_101 = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, borderType = cv2.BORDER_REFLECT_101)
wrap = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, borderType = cv2.BORDER_WRAP)
constant = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, borderType = cv2.BORDER_CONSTANT, value=0)图像结果展示:
1
2
3
4
5
6
7
8
9import matplotlib.pyplot as plt
fig = plt.figure(figsize=(20,8), dpi = 80)
plt.subplot(231), plt.imshow(img, "gray"), plt.title("ORGINAL")
plt.subplot(232), plt.imshow(replicate, "gray"), plt.title("REPLICATE")
plt.subplot(233), plt.imshow(reflect, "gray"), plt.title("REFLECT")
plt.subplot(234), plt.imshow(reflect_101, "gray"), plt.title("REFLECT_101")
plt.subplot(235), plt.imshow(wrap, "gray"), plt.title("WARP")
plt.subplot(236), plt.imshow(constant, "gray"), plt.title("CONSTANT")
plt.show()
-
数值计算规则
使用广播原则,总的加多少,对应的下部分就加多少
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21img_cat = cv2.imread("cat.jpg")
img_dog = cv2.imread("dog.jpg")
img_cat2 = img_cat + 10
print(img_cat[:5,:,0])
'''
array([[142, 146, 151, ..., 156, 155, 154],
[108, 112, 118, ..., 155, 154, 153],
[108, 110, 118, ..., 156, 155, 154],
[139, 141, 148, ..., 156, 155, 154],
[153, 156, 163, ..., 160, 159, 158]], dtype=uint8)
'''
print(img_cat2[:5,:,0])
'''
array([[152, 156, 161, ..., 166, 165, 164],
[118, 122, 128, ..., 165, 164, 163],
[118, 120, 128, ..., 166, 165, 164],
[149, 151, 158, ..., 166, 165, 164],
[163, 166, 173, ..., 170, 169, 168]], dtype=uint8)
'''
# 可以看到img_cat2中每一个位置相较于img_cat中的位置都加了10在numpy中加减和在opencv中加减的规则还不一样
1
2
3
4
5
6
7
8
9# 如果在numpy中相加之后的数据大小,超过255的话 相当于对255取余
(img_cat + img_cat2)[:5,:,0]
'''
array([[ 38, 46, 56, ..., 66, 64, 62],
[226, 234, 246, ..., 64, 62, 60],
[226, 230, 246, ..., 66, 64, 62],
[ 32, 36, 50, ..., 66, 64, 62],
[ 60, 66, 80, ..., 74, 72, 70]], dtype=uint8)
'''1
2
3
4
5
6
7
8
9# 在opencv中使用add操作的时候,当数值超过255的话,则按照255算
cv2.add(img_cat , img_cat2)[:5,:,0]
'''
array([[255, 255, 255, ..., 255, 255, 255],
[226, 234, 246, ..., 255, 255, 255],
[226, 230, 246, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255]], dtype=uint8)
''' -
图像大小的改变
resize方法
InputArray src :输入,原图像,即待改变大小的图像;
OutputArray dst: 输出,改变后的图像。这个图像和原图像具有相同的内容,只是大小和原图像不一样而已;
dsize:输出图像的大小,其中,fx和fy就是下面要说的两个参数,是图像width方向和height方向的缩放比例。
fx:width方向的缩放比例
fy:height方向的缩放比例interpolation :这里只将
interpolation设定为cv.INTER_AREA。值得注意的是,当缩小图片时,cv.INTER_AREA效果较好,当放大图片时,cv.INTER_CUBIC或cv.INTER_LINEAR效果较好。1
2
3
4resize(InputArray src, OutputArray dst, Size dsize,
double fx=0, double fy=0, int interpolation=INTER_LINEAR )
res = cv2.resize(img, (0,0), fx=3, fy=1) -
图像的翻转和旋转
-
图像的翻转:
flip(src, flipCode[, dst])
flipCode=0 表示上下翻,
flipCode>0 表示左右翻转
flipCode<0 上下+左右
-

1 | import cv2 |
-
图像的旋转:
rotate(src, rotateCode[, dst])
Rotate by 90 degrees clockwise (rotateCode = ROTATE_90_CLOCKWISE).
Rotate by 180 degrees clockwise (rotateCode = ROTATE_180).
Rotate by 270 degrees clockwise (rotateCode = ROTATE_90_COUNTERCLOCKWISE).
COUNTERCLOCKWISE逆时针,CLOCKWISE顺时针
1 | import cv2 |
形态学的操作
腐蚀操作
cv2.erode(img, kernel, iterations)
1 | img = cv2.imread("opencv.png") |
原先图像:

腐蚀操作之后的图像:

我们可以看到 图像中的一些杂线就会被抹去,但是带来的负面影响就是图像本身也变细了
膨胀操作
cv2.dilate(需要膨胀的图像, 核, 迭代次数)
1 | img = cv2.imread("opencv.png") |
膨胀前的图像:

膨胀后的图像:

明显就变粗了许多
开运算
开运算就是把上面两种运算结合起来,
开: 先腐蚀在膨胀
1 | # 开 : 先腐蚀在膨胀 |
开运算前的图像:
开运算后的图像:

从这里可以看出开运算既可以把杂边去掉也可以保持原来的图像损害不大
闭运算
闭运算和开运算相对:先膨胀在腐蚀:
1 | 闭运算:先膨胀,再腐蚀 |
闭运算之前的图像
闭运算之后的图像:
可以看出这两个图像几乎没有差别
梯度的运算
梯度:膨胀 - 腐蚀
cv2.morphologyEx(图像, cv2.MORPH_GRADIENT, kernel)
1 | # 梯度:膨胀 - 腐蚀 |
膨胀和腐蚀操作的图像为:

梯度的图像为:

礼帽与黑帽
- 礼帽:原始输入 - 开运算结果
- 开运算可以消除暗背景下的高亮区域,那么如果用原图减去开运算结果就可以得到原图中灰度较亮的区域,所以又称白顶帽变换。
- 黑帽:闭运算 - 原始输入
- 闭运算可以删除亮背景下的暗区域,那么用原图减去闭运算结果就可以得到原图像中灰度较暗的区域,所以又称黑底帽变换。
1 | # 礼帽 |
礼帽:

黑帽:

图像梯度-Sobel算子
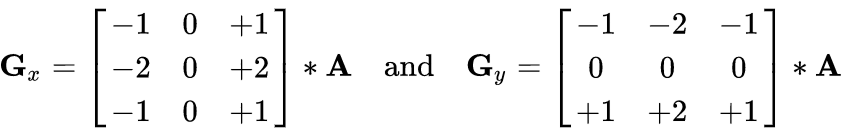
dst = cv2.Sobel(src, ddepth, dx, dy, ksize)
- ddepth:图像的深度
- dx和dy分别表示水平和竖直方向
- ksize是Sobel算子的大小
1 | img = cv2.imread("pie.png", cv2.IMREAD_GRAYSCALE) |
原图像为:

结果为:

图像显示不全面,白到黑是正数,黑到白是负数,所有的负数都会被截断成零,所以要取绝对值
1 | # 读入图像 |
结果为:

我们上面计算的都是x方向的梯度,y方向的梯度和上面方法相似,
我们还可以计算x和y方向的图像
1 | # 读入图像 |
操作结果为:

图像梯度- Scharr算子
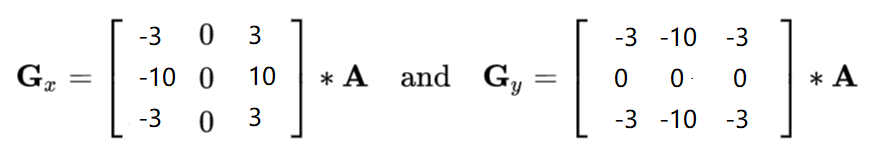
Scharr算子相较于Sobel算子来说差异更为明显,细节之处更能体现出来,对梯度更加敏感
图像梯度:laplacian算子
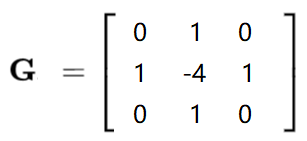
laplacian算子:退出一阶导,对一些变化更为敏感,但是可能受噪音影响
不同算子之间的差异
1 | # 不同算子之间的差异 |
最后结果为:
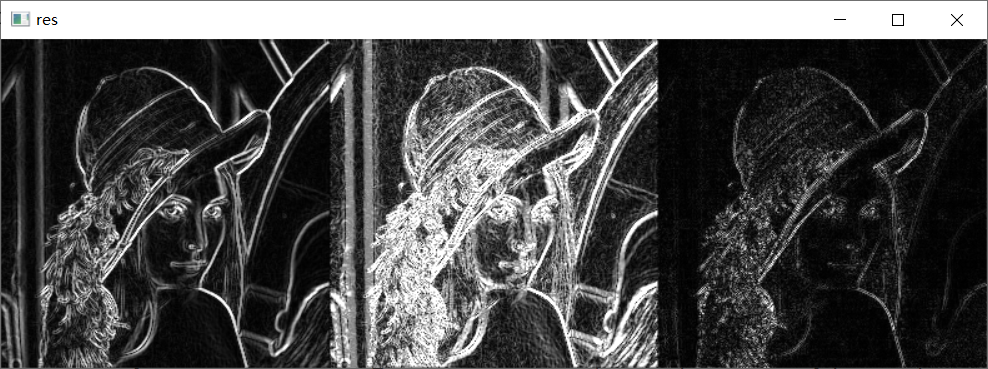
图像的滤波操作
傅里叶变换
我们生活在时间的世界中,早上7:00起来吃早饭,8:00去挤地铁,9:00开始上班。。。以时间为参照就是时域分析。
但是在频域中一切都是静止的!
https://zhuanlan.zhihu.com/p/19763358
傅里叶变换的作用
-
高频:变化剧烈的灰度分量,例如边界
-
低频:变化缓慢的灰度分量,例如一片大海
滤波
-
低通滤波器:只保留低频,会使得图像模糊
-
高通滤波器:只保留高频,会使得图像细节增强
-
opencv中主要就是cv2.dft()和cv2.idft(),输入图像需要先转换成np.float32 格式。
-
得到的结果中频率为0的部分会在左上角,通常要转换到中心位置,可以通过shift变换来实现。
-
cv2.dft()返回的结果是双通道的(实部,虚部),通常还需要转换成图像格式才能展示(0,255)。
1 | import numpy as np |
1 | import numpy as np |
1 | img = cv2.imread('lena.jpg',0) |
图像滤波可以去除噪音:
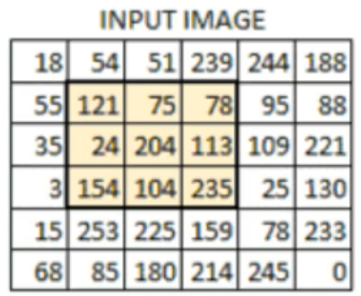
我们要处理的图像:

有四种滤波操作:
-
均值滤波:简单平均的卷积操作
1
2
3
4
5img = cv2.imread("lenaNoise.png")
# blur参数:被处理图像,卷积大小
blur = cv2.blur(img, (3, 3))
cv_show('blur', blur)操作后的结果:
我们可以看出虽然噪音降低了,但是还有有噪音
-
方框滤波:基本和均值一样,可以选择归一化
1
2
3
4
5
6
7
8
9
10
11
12# 方框滤波
# 基本和均值一样,可以选择归一化 容易越界, 如果使用归一化的话,该方法和均值滤波一样,如果不进行归一化的,那么3*3的核内数据相加,但是没有除9的操作,这样如果超过255的话则按照255计算
# boxFilter三个参数
# 第一个:要处理的图像,
# 第二个:使用-1表示处理之后的图像和原始图像颜色通道一致
# 第三个:卷积核大小
# 第四个: 是否进行归一化
box = cv2.boxFilter(img, -1, (3,3), normalize = True)
cv_show("box", box)
box = cv2.boxFilter(img, -1, (3,3), normalize = False)
cv_show("box", box)使用归一化参数:
不使用归一化参数:
-
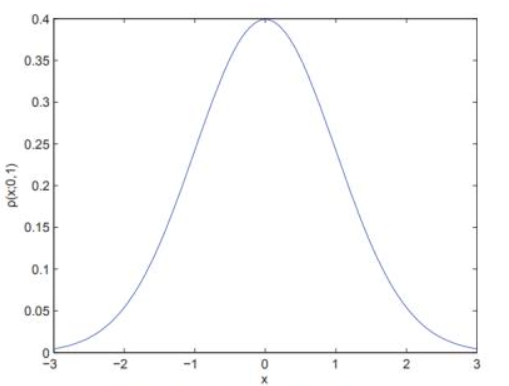
高斯滤波:高斯模糊的卷积核里的数值是满足高斯分布的,相当于更重视中间的数据
就是中间的数值权重更大一些,有一个权重矩阵
1
2
3aussian = cv2.GaussianBlur(img, (5,5), 1)
cv_show("aussian", aussian)



结果图:噪音点减少

-
中值滤波:相当于用中值代替
将数据从小到大排好序,选取中间的数据作为标准
1
2
3median = cv2.medianBlur(img, 5)
cv_show("median", median)处理结果:

可以看出噪音点几乎全部消失了,代价是图像变得不那么清晰
所有滤波相互比较

图像的阈值
ret, dst = cv2.threshold(src, thresh, maxval, type)
- src:输入图,只能输入单通道图像,通常来说为灰度图
- dst:输出图
- thresh:阈值
- maxval:当像素值超过了阈值(或者小于阈值,根据type来决定),所赋予的值
- type:二值化操作的类型,包含以下5种类型: cv2.THRESH_BINARY; cv2.THRESH_BINARY_INV; cv2.THRESH_TRUNC;cv2.THRESH_TOZERO;cv2.THRESH_TOZERO_INV
- cv2.THRESH_BINARY 超过阈值部分取maxval(最大值),否则取O
- cv2.THRESH_BINARY_INV THRESH_BINARY的反转
- cv2.THRESH_TRUNC大于阈值部分设为阈值,否则不变
- cv2.THRESH_TOZERO大于阈值部分不改变,否则设为0
- cv2.THRESH_TOZERO_INV THRESH_TOZERO的反转
五种形式的展示:
1 | img = cv2.imread("cat.jpg", cv2.IMREAD_GRAYSCALE) |
结果图像:

Canny边缘检测
- 使用高斯滤波器,以平滑图像,滤除噪声
- 计算图像中每个像素点的梯度强度和方向
- 应用非极大值(Non-Maximum Suppression)抑制,以消除边缘检测带来的杂散相应
- 应用双阀值(Double-Threshold)检测来确定真实和潜在的边缘
- 通过抑制孤立的弱边缘最终完成边缘检测
-
高斯滤波器
-
梯度和方向
-
非极大值抑制

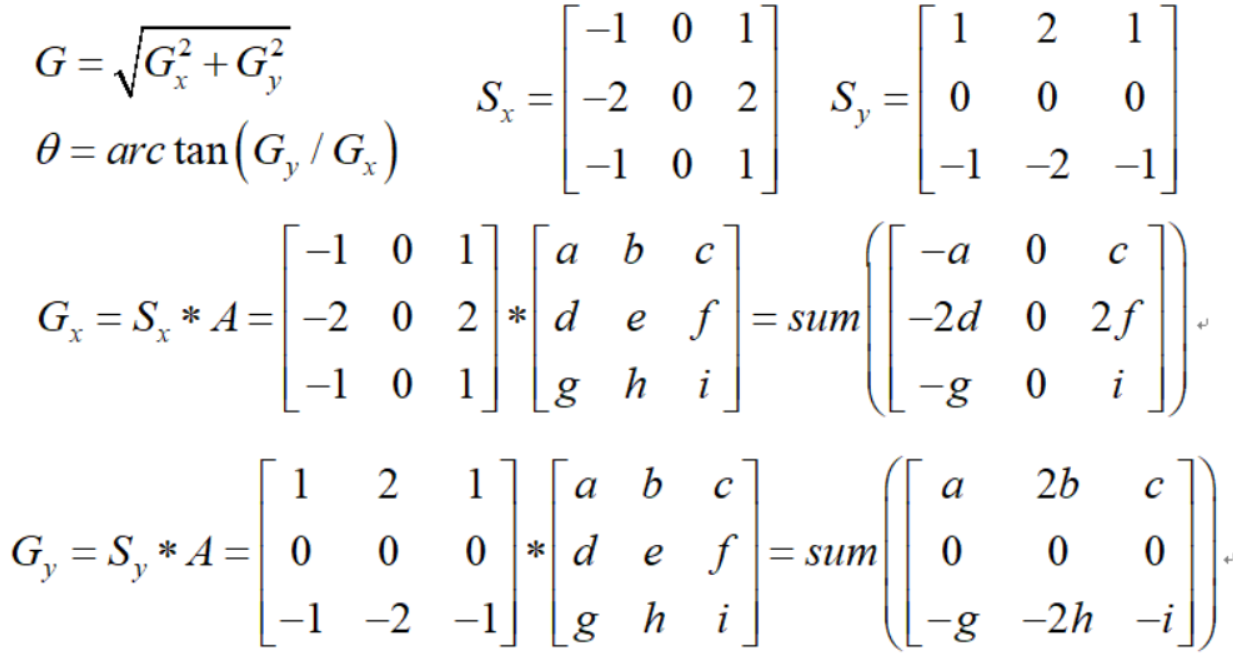
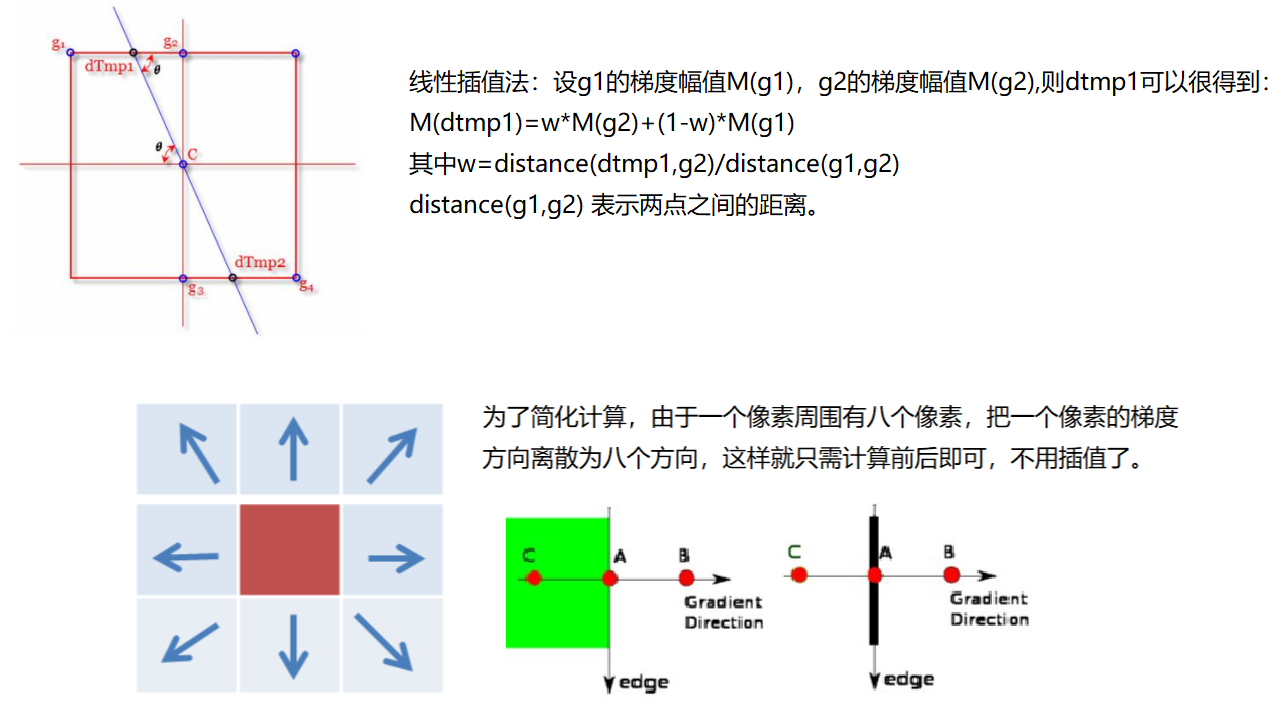
- 双阈值检测

函数调用比较简单:
直接调用Canny函数
1 | # 双阈值检测 |
结果图

金字塔特征提取
-
高斯金字塔
-
拉布拉斯金字塔
高斯金字塔:向下采样方法(缩小)

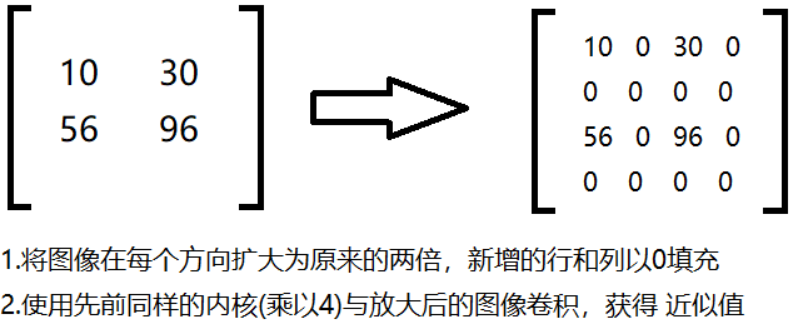
高斯金字塔:向上采样方法(放大)
1 | # 导入图像 |
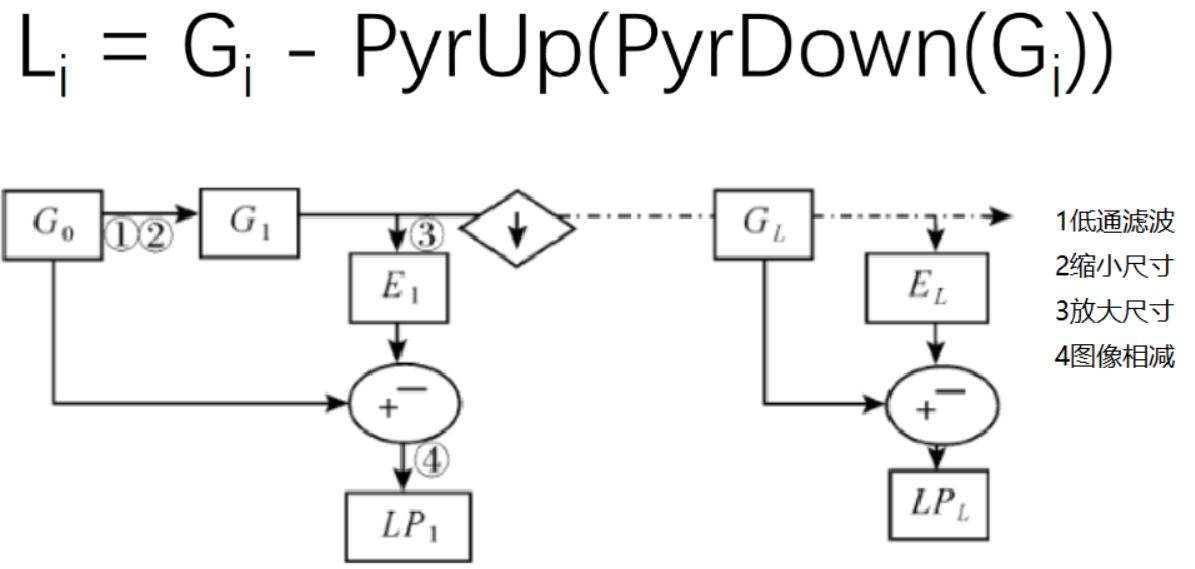
拉普拉斯金字塔:
方法:先使用低通滤波缩小原来图像的尺寸, 然后再放大尺寸,最后让原始图像减去放大之后的图像数据
1 | # 进行10次拉普拉斯方法 |
图像轮廓获取
contours, hierarchy = cv2.findContours(img, mode, method)
返回两个参数:
第一个:各个轮廓组成的元组
第二个:是轮廓的层级
mode: 轮廓检索模式
- RETR_EXTERNAL : 质检所最外面的轮廓
- RETR_LIST: 检索所有轮廓,并将其报错到一条链表当中
- RETR_CCOMP: 检索所有轮廓,并将他们组织成两层:顶层是各部分的外部边界,第二层是空洞的边界
- RETR_TREE: 检索所有的轮廓,并重构嵌套轮廓的整个层次
method:轮廓逼近方法
- CHAIN_APPROX_NONE: 以Freeman连码的方式输出轮廓,所有其他方法输出多边形(顶点的序列)。
- CHAIN_APPROX_SIMPLE: 压缩水平的,垂直的和斜的部分,也就是函数只保留他们的终点部分

为了使轮廓获取更加精确,建议使用二值图像
1 | # 获取原始图像 |
图像轮廓的绘制
drawContours(imgae, contours, num, bgr, width)
参数:第一个 是需要在那个图像上绘制, 第二个是findContours返回的轮廓, 第三个是第几个轮廓,第四个是轮廓颜色,第五个是轮廓线条宽度
1 | # 传入绘制图像,轮廓,轮廓索引,颜色模式,线条厚度 |
原始图像 :
轮廓图像:
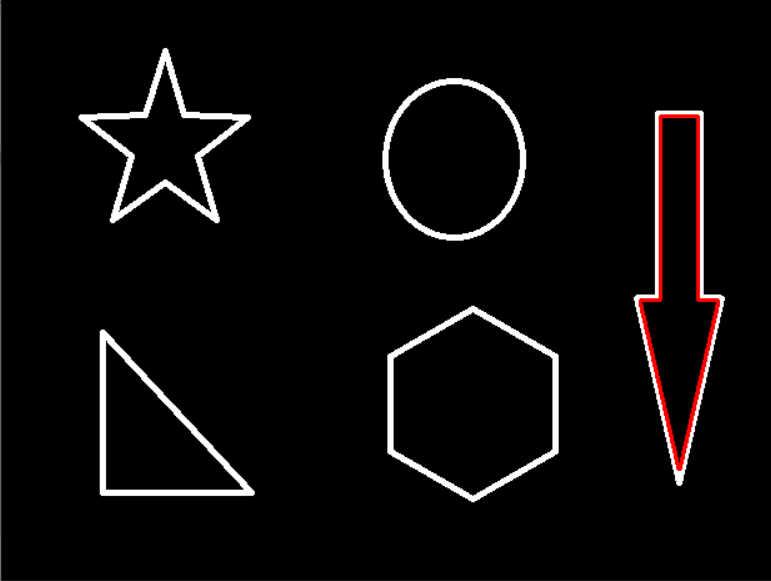
轮廓特征
我们在使用findContours函数获取到轮廓元组的时候,元组中每一个参数都代表着一个轮廓
1 | # 获取到第0个轮廓 |
轮廓近似
当我们遇到不规则的轮廓的时候,如果想要近似称为一个比较规则的图像的时候,这时候我们就要用到轮廓近似

1 | # 获取原始图像 |
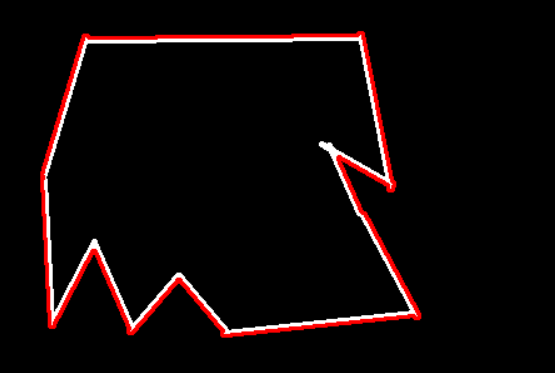
轮廓近似函数:cv2.approxPolyDP(轮廓, 精度, 是否闭合)
1 | epsilon = 0.1 * cv2.arcLength(cnt, True) |
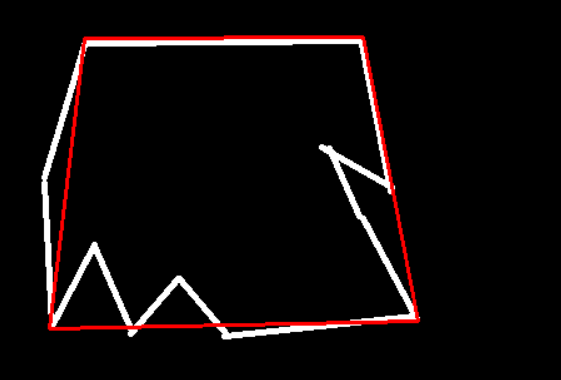
边界轮廓
我们可以指定轮廓的形状
比如说我想要这个图像的边界轮廓图像为矩形:
1 | # 读取图像 |
近似轮廓与轮廓的面积比
1 | area = cv2.contourArea(cnt) |
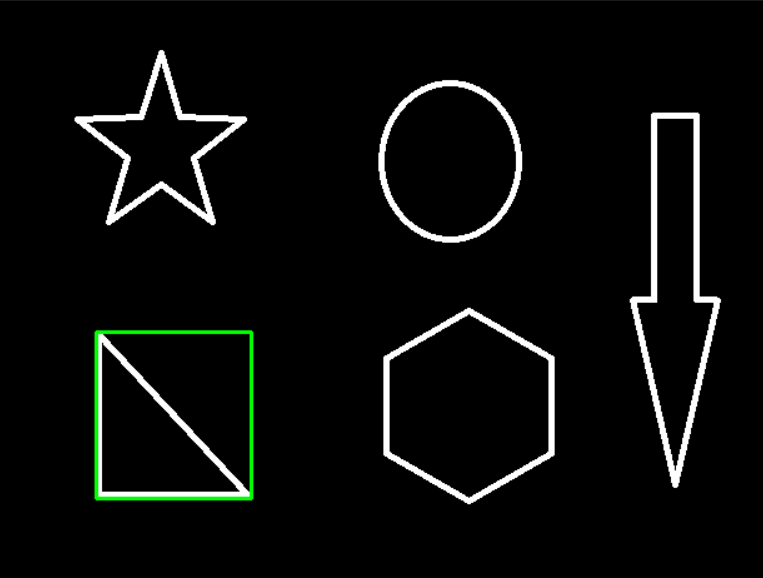
外接圆形状的
1 | # 获取中点坐标和半径 |
模板匹配
模板匹配和卷积原理很像,模板在原图像上从原点开始滑动,计算模板与(图像被模板覆盖的地方)的差别程度,这个差别程度的计算方法在opencv里面有6种,然后将每次计算的结果放在一个矩阵中,作为结果输出。假如原图形是AxB大小,而模板是axb大小,则输出的结果矩阵是(A-a+1)x(B-b+1)
cv2.matchTemplate(img, template, method)
method方法
- TM_SQDIFF:计算平方不同,计算出来的值越小,越相关
- TM_CCORR:计算相关性,计算出来的值越大,越相关
- TM_CCOEFF:计算相关系数,计算出来的值越大,越相关
- TM_SQDIFF_NORMED:计算归一化平方不同,计算出来的值越接近0,越相关
- TM_CCORR_NORMED:计算归一化相关性,计算出来的值越接近1,越相关
- TM_CCOEFF_NORMED:计算归—化相关系数,计算出来的值越接近1,越相关
当我们使用完rec = cv2.matchTemplate() 函数后返回值是, 匹配完之后的信息
我们使用min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res) 获取 相关值的最小值,最大值,最小位置,最大位置
1 | # 模板匹配 |






匹配多个对象
1 | img_rgb = cv2.imread('test.png') |








